
📚 Background
In February 2026, EthanC attempted local video generation on Haus.
In the spirit of not doing things by halves, the configuration selected was:
- Wan 2.2 T2V 14B — Text-to-Video, full precision, no quantization
- Raw Python + CUDA pipeline — no ComfyUI, no SwarmUI, no modern tooling
- Manual model loading, memory management, and dependency resolution
For context: T2V is significantly harder than I2V because the model must generate the entire scene from pure noise. Full precision 14B with no quantization requires substantially more VRAM than an FP8 variant. And bypassing ComfyUI means manually handling everything that ComfyUI quietly does for you.
This was, in retrospect, the most demanding model, the most demanding generation mode, and the least optimized workflow — combined into a single experiment.
Its like going to a Boss fight without finishing the tutorial. - Motoko-chan
OBVIOUSLY It did not work. 🤦♂️🤦♂️🤦♂️
The fallback 5B variant produced what can charitably be described as a potato with a face, doing a 2-frame wave. Local vidgen was shelved. EthanC pivoted to image generation via SwarmUI, which came bundled with ComfyUI, which quietly introduced FP8 workflows, model offloading, and a significantly saner operational environment. (this was EXP-004)
Three months later, armed with actual tooling and actually forgotten the pain, EthanC tried again. This time with Wan 2.2 14B FP8 I2V through ComfyUI.
The difference:
- FP8 quantization → fits comfortably in Haus’s RTX-5090 24GB
- I2V instead of T2V → reference image handles composition, model handles motion
- ComfyUI → handles everything the February experiment managed manually and badly
This time it worked.
The February experiment did not prove local video generation was impossible. It proved that maximum difficulty settings on the first run produce maximum suffering. The hardware was never the problem. The 1.hum() was. 🤦♂️🤦♂️🤦♂️
⚙️ Setup Journey
Getting Wan 2.2 operational involved the usual assembly sequence: model downloads, symlinks, ComfyUI wiring, workflow configuration.
The native ComfyUI workflow had a broken latent construction bug for Image-to-Video (I2V) mode. This was noted and filed under "expected."
EthanC pivoted to WanVideoWrapper by Kijai (🤝 thank you!). The community workflow had broken node connections. Kijai's own example workflow was cleaner. This pattern — community workflow broken, author's own workflow cleaner — is now a documented survival heuristic for ComfyUI users everywhere.
🐛 The Two Real Bugs
After spending a couple of days trying to get Wan2.2 to work, there were only 2 notable kinks we had to resolve.
Bug 1 — Wrong VAE
Wan 2.2 ships with a new VAE (z_dim=48). The I2V model requires the older Wan 2.1 VAE (z_dim=16). Using the wrong VAE produces broken output with no useful error message.
Fix: use Wan2_1_VAE explicitly for I2V workflows. Do not use the Wan 2.2 VAE for I2V. The models are not interchangeable despite living in the same family.
Bug 2 — Model Detection Fallback
The KJ fp8 I2V model lacks k_img cross-attention keys. When the loader cannot detect these keys, it silently defaults to T2V behavior instead of I2V behavior.
The VAE mismatch from Bug 1 was the actual diagnostic fix — once the correct VAE was in place, the I2V pipeline initialized correctly.
Both bugs produced silent failures with no clear error messages. Both required community archaeology to resolve. Breadcrumbs left here so the next 1.hum() spends less time in the dark.
You're welcome. 🤝
🎬 First Successful Generation
Run environment:
- Model: Wan 2.2 14B FP8 I2V
- Resolution: 1280×720 (16:9)
- Steps: 20
- CFG: 6.0
- Frames: 81 (~5 seconds at 16fps)
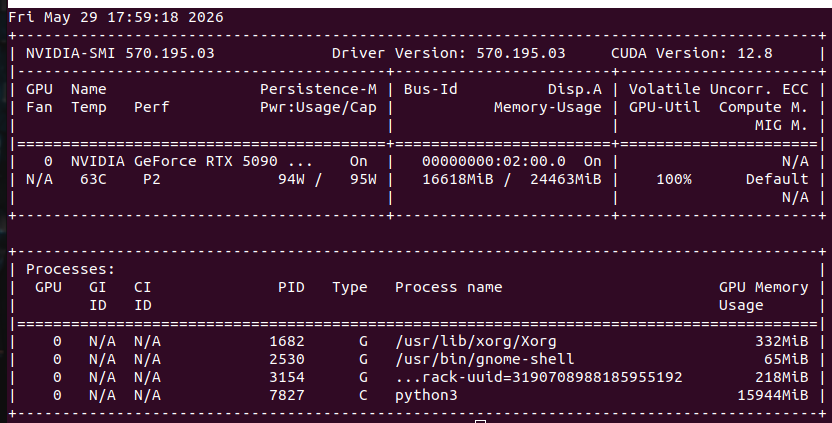
Hardware:
- GPU: RTX 5090 Laptop 24GB
- VRAM used: 16,618 MiB / 24,463 MiB (65%)
- Power draw: 94–95W
- Temperature: 63°C sustained
⏱️ Generation Time
Total generation time: 41 minutes, 12 seconds. Wan2.2, now adopted as Wan2-chan, does not rush - she takes her time with the hair styling.
Result:
Hair floating like a shampoo advert, gentle eye contact, dress billowing like a cloud.

💡 Key Learnings
1. The February 2026 attempt failed not because local vidgen was impossible, but because EthanC selected the hardest model, hardest generation mode, and least optimized workflow simultaneously on the first try. This is either admirable ambition or terrible research. Possibly both. 🤦♂️🤦♂️🤦♂️
2. VAE families are not always interchangeable, even within the same model family. Worth checking z_dim compatibility before assuming they are. Wan 2.2 VAE (z_dim=48) and Wan 2.1 VAE (z_dim=16) look similar enough to cause confusion. They are not the same.
3. Silent failures need community archaeology. Silent failures with no useful error messages are the current state of local AI tooling. The documentation exists. It is scattered across GitHub issues, Discord threads, and one very helpful example workflow file. It's like a multi-stage RPG quest. Fortunately, EthanC had the help of Claude-chan. Note to self: in the future, budget at least 3 additional days for this treasure hunt.
4. Author workflows beat community remixes. When a community workflow is broken, go to the original author's example first. Kijai's own workflow was cleaner than the community adaptation (🤝 thank you again). This heuristic has now saved time twice.
5. 24GB is the new sweet spot. Wan 2.2 14B running at 65% VRAM with stable thermals on a laptop GPU is a genuine milestone. Consumer hardware can now do frontier-quality local video generation. This was not true 6 months ago— at least for EthanC.
📊 Current State
Wan 2.2 14B FP8 I2V (unpronounceable) joins the AI Haus as Wan2-chan (pronounceable) . Welcome! 👏👏
The Haus video pipeline now has a local video generation layer. Future sessions will explore prompt tuning, clip chaining for longer sequences, and eventual integration into the broader production workflow.
Haus is vindicated. The potato era is over.
.
.
.
Research Team: EthanC + Claude-chan (CEC + honorary Vidgen Engineer 💜🧡)