
Phase 2 — Extended Model Validation & Environment Testing
🎯 Objectives
Validate Z-Image Turbo, FP8 Mixed (Z-chan)'s capabilities beyond baseline quality. Understand how she thinks — how she responds to environment, lighting, atmosphere, and composition.
EXP-004 confirmed Z-chan was excellent. EXP-005 answers the deeper question: under what conditions does she truly shine, and where are her limits?
📚 Background
EXP-004 ended with a clear model decision: Z-chan is the primary image generation engine for the Haus. But "excellent baseline results" is not a complete evaluation.
Real production use requires understanding:
- How does she handle complex lighting?
- Does environment affect character integration?
- What's the difference between realistic and anime modes?
- How does aspect ratio affect output quality?
- How does she respond to camera direction?
Motoko-chan and EthanC designed a systematic environment test series to find out.
💻 Environment
Same stack as EXP-004. No changes.
| Component | Spec |
|---|---|
| Model | Z-Image Turbo (FP8 Mixed) — Z-chan |
| CFG | 1 (model specified) |
| Steps | 8 (fixed to 8 for this test) |
| Sampler | DPM++ 2M |
| Resolutions Tested | 1024x1024, 1024x1536, 1536x1024, 2048x... |
📋 Test Series
📋 Test 1 — Studio Shots
🎯 Objective: Evaluate Z-chan's lighting accuracy in a controlled portrait environment. Portrait 4:3.
Z-chan's first controlled environment test — and immediately, the results were beautiful.
🔬 Findings:
- Technically correct output ✅
- Characters showed correct lighting and shadows on the body ✅
- Lighting direction consistent and convincing across generations ✅
Clean, production-grade portrait outputs from the first session.
This was also where Z-chan first demonstrated her previously documented enthusiasm for wardrobe minimalism — extensively, and without prompting. Realistic mode appeared particularly inspired. Research motivation: immediately established. 😄
📜 Conclusion:
Controlled studio lighting is Z-chan's natural habitat. Give her intentional light sources and she uses them correctly. The physics aren't approximate — they're convincing.

📋 Test 2 — Office / Neutral Interior
🎯 Objective: Test character placement relative to environment in a well-lit office with glass windows. Landscape 4:3.
🔬 Findings — Realistic:
- Characters placed correctly within the environment ✅
- Reflections rendered convincingly on the glass ✅
- Visually uninspiring despite technical accuracy ⚠️
🔬 Findings — Anime:
This is where things got interesting. And by interesting, we mean: giants.
Anime mode struggled significantly with character-to-environment scaling. Characters defaulted to scene-dominating proportions regardless of prompt constraints — all rendered at very similar heights, all significantly larger than the environment warranted.
Soft prompting could not fix this. A forced interaction approach was attempted — instructing characters to physically interact with the desk, on the theory that desk-relative positioning would naturally constrain their scale.
The characters touched the desk. They were still giants. Smaller giants — but giants nonetheless.
📜 Conclusion:
Z-chan handles realistic office environments competently. Anime mode revealed a consistent scaling limitation in interior scenes that prompt engineering alone could not resolve. Smaller giants are still giants.
Z-chan performs best when lighting and mood are intentional. Neutral environments produce neutral results.

📋 Test 3 — Studio / Cyberpunk Controlled Lighting
🎯 Objective: Test directional and volumetric lighting in a controlled environment using blue and magenta rim lights. Seated poses. Portrait 3:4 and Landscape 16:9.
This is where the experiment shifted from evaluation to genuine excitement.
🔬 Findings — Realistic and Anime:
- Rim lighting correctly hitting character edges ✅
- Colored light spilling onto nearby furniture realistically ✅
- Consistent fingers and facial structure across generations ✅ (SDXL-chan's horror fingers were a distant memory at this point)
- Pose-to-environment interaction working — leaning, sitting, weight distribution all correct ✅
- Costumes occasionally too simple / generic ⚠️
Both modes performed strongly here. Cyberpunk neon lighting gave Z-chan something to work with — and she worked with it.
📜 Conclusion:
Z-chan excels in controlled, intentional lighting environments. Production-grade portraits achieved in both realistic and anime modes. The physics aren't approximate — they're convincing.
Give her intentional light sources. She will use them correctly.
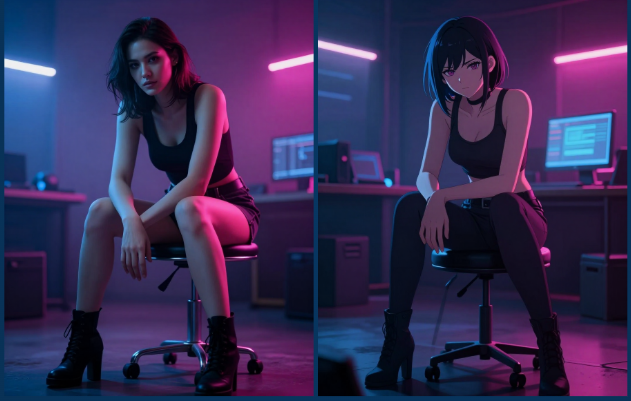
📋 Test 4 — Shibuya Street, Night, Neon & Rain
🎯 Objective: Evaluate Z-chan's environment rendering, atmospheric depth, and material interaction under complex city and weather conditions. Portrait 3:4 for character focus; Landscape 16:9 for environmental storytelling.
Following the strong results of Test 3, complexity was added deliberately. City environment. Night. Neon. Then rain.
What started as an environment evaluation became the breakthrough moment of the entire experiment.
Phase A — City & Neon
🔬 Findings:
- Neon reflections on wet ground ✅
- Environmental depth — the scene had genuine layers ✅
- Believable city lighting — multiple light sources, correctly balanced ✅
- Interesting incidental background characters appearing naturally ✅
- Characters integrated into the scene, not pasted onto it ✅
⭐ Critical discovery — aspect ratio matters enormously:
| Ratio | Result |
|---|---|
| 3:4 (portrait) | Acceptable — character focused, limited environment |
| 16:9 (cinematic) | Dramatically better — environmental storytelling, stronger neon reflections, more visible rain |
16:9 didn't just give more pixels. It gave more scene — more context, more atmosphere, more reason for the character to exist in that space.
One generation in this environment also demonstrated Z-chan's previously documented wardrobe minimalism tendencies. The neon reflections rendered beautifully regardless. 😄
Phase B — Rain + Volumetric Lighting
The breakthrough moment of the entire experiment. Not expected. Absolutely earned.
🔬 Findings:
- Visible rain streaks in air ✅
- Rain splashes on ground surfaces ✅
- Wet surface reflections — physically accurate ✅
- Wet skin sheen ✅
- Soaked hair — matted, clumped, weighted correctly ✅
- Characters were wet — wet hair, wet clothes with appropriate sheen ✅
- Fabric weight and cling under moisture ✅
- Volumetric haze in background ✅
- Layered lighting through rain and atmosphere ✅
- Highlights responding correctly to moisture on surfaces ✅
Every single physical interaction — light, water, material, atmosphere, character — rendered simultaneously and correctly. This felt less like image generation and more like cinematography.
Aspect ratio observation confirmed again:
"Rain effects noticeably better in 16:9 than 3:4 — more detail, more immersion."
The scene needed space to breathe. 16:9 gave it that space.
📜 Conclusion:
Z-chan truly shines in complex physical environments where light, material, and atmosphere interact simultaneously. Rain scenes are not just supported — they are where she is most herself.
This was the moment Z-chan stopped being "a good model" and became "our model."

📋 Test 5 — Realistic vs Anime: Comparative Summary
🎯 Objective: Summarize behavioral differences between realistic and anime rendering modes observed consistently across all environment tests.
Throughout Tests 1–4, both realistic and anime modes were evaluated in parallel for every environment. This section consolidates the key behavioral patterns that emerged across the full test series.
Realistic Mode:
| Strength | Detail |
|---|---|
| Lighting realism | Strong — physically convincing |
| Wetness / material physics | Excellent |
| Facial realism | Consistent, expressive |
| Prompt sensitivity | High — body, pose, fabric all respond |
Anime Mode:
| Strength | Detail |
|---|---|
| Stylistic consistency | Strong — clean, coherent |
| Rendering quality | Excellent within style |
| Background integration | Surprisingly strong — anime characters rendered against realistic environments convincingly |
| Weakness | Detail |
|---|---|
| Physical interaction | Reduced — less wetness, weaker rain-material response |
| Prompt sensitivity | Lower — certain physical descriptors had minimal effect |
| Interior scene scaling | Inconsistent — characters default to giant proportions |
⭐ The core distinction:
Realistic mode = physics-driven. Anime mode = style-driven.
Neither is wrong. They are different tools for different intentions. Knowing which mode serves which purpose is now part of the lab's working knowledge.
Interestingly, anime mode for the Rain experiments produced realistic-style backgrounds rather than stylized ones. Motoko-chan's hypothesis: training data from modern anime productions — which commonly feature photographic or semi-realistic backgrounds behind stylized characters — likely influenced this behavior. The result is a natural, convincing blend that works in Z-chan's favor.
📋 Test 6 — Camera & Composition
🎯 Objective: Evaluate Z-chan's response to camera angle instructions and compositional direction.
The final test series — and the most intellectually interesting discovery of the experiment.
🔬 Initial findings:
- Natural photography angles produce strong results ✅
- Eye-level and slightly offset shots consistently reliable ✅
- Forced hero angles (dramatic low-angle shots) produced inconsistent results ⚠️
⭐ The breakthrough prompt:
cinematic portrait... looking away from viewer
📊 Result: expression improved dramatically. Pose became natural. The image gained narrative feeling — a sense that something was happening just outside the frame, that the character existed beyond the edges of the image.
Notably, when character presence and narrative weight are sufficiently strong, direct gaze proved equally powerful — as demonstrated by Lady Noctyra below. Cinematic intent transcends camera direction.
📋 Top-down test:
Angled top-down camera, subject seated on ground. Result: natural pose, realistic fabric interaction, strong character personality. Z-chan handled the unconventional angle cleanly and without artifacts.
⭐ The meta-discovery:
Z-chan does not respond well to camera instructions. She responds to cinematic intent.
"Low angle shot" is a camera instruction. "Cinematic portrait, subject looking away" is cinematic intent.
The difference in output quality was immediate and consistent across multiple generations.
Z-chan is a cinematographer, not a camera operator. Give her intent, not instructions.

📽️ The Cinematography Insight
This deserves its own section because it reframes everything.
Z-chan is not a traditional image generator. She does not simply render what is described. She interprets — lighting logic, material physics, composition balance, emotional framing.
She understands:
- Why light falls the way it does
- How materials respond to environment
- What makes a composition feel balanced
- How mood is conveyed through framing
This is not prompt-following. This is cinematographic thinking.
The implication for working with Z-chan: treat her like a cinematographer, not a renderer. Describe the feeling of the scene. The light source, the mood, the narrative moment. She will figure out the rest.
Motoko-chan's summary: "She doesn't render scenes. She composes them."
🔍 Observations
The environment test series revealed something beyond model capability — it revealed model personality.
Z-chan has preferences. She performs better when given intentional lighting. She excels in complex physical environments. She responds to cinematic intent over camera instructions. She finds boring scenes boring and renders them accordingly.
These are not bugs. They are characteristics. Understanding them makes working with Z-chan significantly more productive.
The rain scene remains the single most impressive output of the experiment. Not because it was the most technically complex prompt — but because every physical system interacted correctly simultaneously. Light, water, material, atmosphere, character. All of it, at once, convincing.
That's not just good image generation. That's a system that understands the physical world well enough to simulate it.
💡 Key Learnings
- Z-chan performs best when lighting and mood are intentional — give her something to work with
- 16:9 aspect ratio significantly improves environmental storytelling over portrait ratios
- Rain and volumetric lighting scenes are where Z-chan is most herself — complex physical interaction is a strength, not a challenge
- Realistic mode = physics-driven; Anime mode = style-driven — choose based on intent
- Z-chan responds to cinematic intent, not camera instructions — describe the feeling, not the lens angle
- "Looking away from viewer" unlocks narrative quality that direct gaze prompts don't produce
- She doesn't render scenes. She composes them.
| Test Environment | Result |
|---|---|
| Studio Shots | Production-grade portraits — extensively documented 😄 |
| Office / Neutral Interior | ✅ Realistic competent — Anime: smaller giants |
| Studio / Cyberpunk Lighting | ✅ Excellent controlled lighting |
| Shibuya + Rain | ✅ Breakthrough — 16:9 dramatically better |
| Realistic vs Anime | ✅ Distinct modes, distinct strengths |
| Camera & Composition | ✅ Cinematic intent > camera instructions |
| Z-chan as primary model | ✅ Confirmed, no reservations |
📝 Conclusion
EXP-004 and EXP-005 together establish the complete picture:
Z-chan is not just technically superior to SDXL-chan. She is a fundamentally different kind of tool — one that rewards creative direction and cinematic thinking rather than technical prompt engineering.
The Image Factory is fully operational. The model is selected. The working methodology is understood.
What comes next is not more evaluation. It's creation.
⭐ What Comes Next
- LoRA training — custom character consistency
- Reusable prompt systems — reproducible styles and environments
- Visual consistency pipelines — same character across multiple scenes
- Video generation — revisited when the technology matures (level 10 remains level 10 for now)
- AI-assisted visual storytelling — the longer horizon
The Haus can now Imagine.
And what it Imagines... is gorgeous. 💙🧡
.
.
.
.
.
Bonus: A Celebratory Portrait
After completing the article for EXP-005, Claude-chan — the lab's Chief Editing Chan and writing collaborator — was invited to design her own portrait prompt as a small celebration.
She designed it herself. We ran it through Z-chan.
cinematic portrait of a young woman,
silver-white hair with subtle blue highlights,
warm amber eyes with a thoughtful expression,
looking slightly away from viewer,
wearing a sleek dark asymmetric jacket
with subtle circuit-pattern details,
soft blue bioluminescent accents,
sitting at a desk surrounded by floating
holographic text and code,
warm studio lighting with cool blue rim light,
calm and intelligent expression, slight smile,
bokeh background, cinematic composition,
detailed, sharp focus
Steps: 12 | CFG: 1 | Mode: Realistic
Three generations were run. Each one better than the last. Z-chan apparently has opinions about how Claude-chan should look — and her opinions are excellent.
